Ubuntu16.04LTS上に構築したJupyter Notebook環境でMNIST手書き数字データベースを使用しKerasで機械学習を実行します。
MNIST手書き数字を使用するチュートリアルはネット上に多数アップされています。ですがそのほとんどは機械学習の成果としてAcc(正解率)やloss(損失率)を数字又はグラフで表示しているだけです。今一つ機械学習の有効性がわかりません。
そこで当記事では機械学習の検証結果を視覚的に理解できる形で出力することでその有効性を確認したいと思います。具体的にはテストデータイメージ(問題)とその機械学習検証結果(答え)を対にして出力しその判定結果を評価します。
目次
1.MNISTデータの確認
今回使用するのは、mnistライブラリに含まれるアメリカ国立標準技術研究所(NIST)が用意した手書き数字の画像データベースです。手書き数字画像は28×28ドットのピクセルデータです。数字画像データベースは6万枚分のトレーニング(学習)データと1万枚分のテスト(訓練)データから構成されています。
(1)手書き文字確認コード
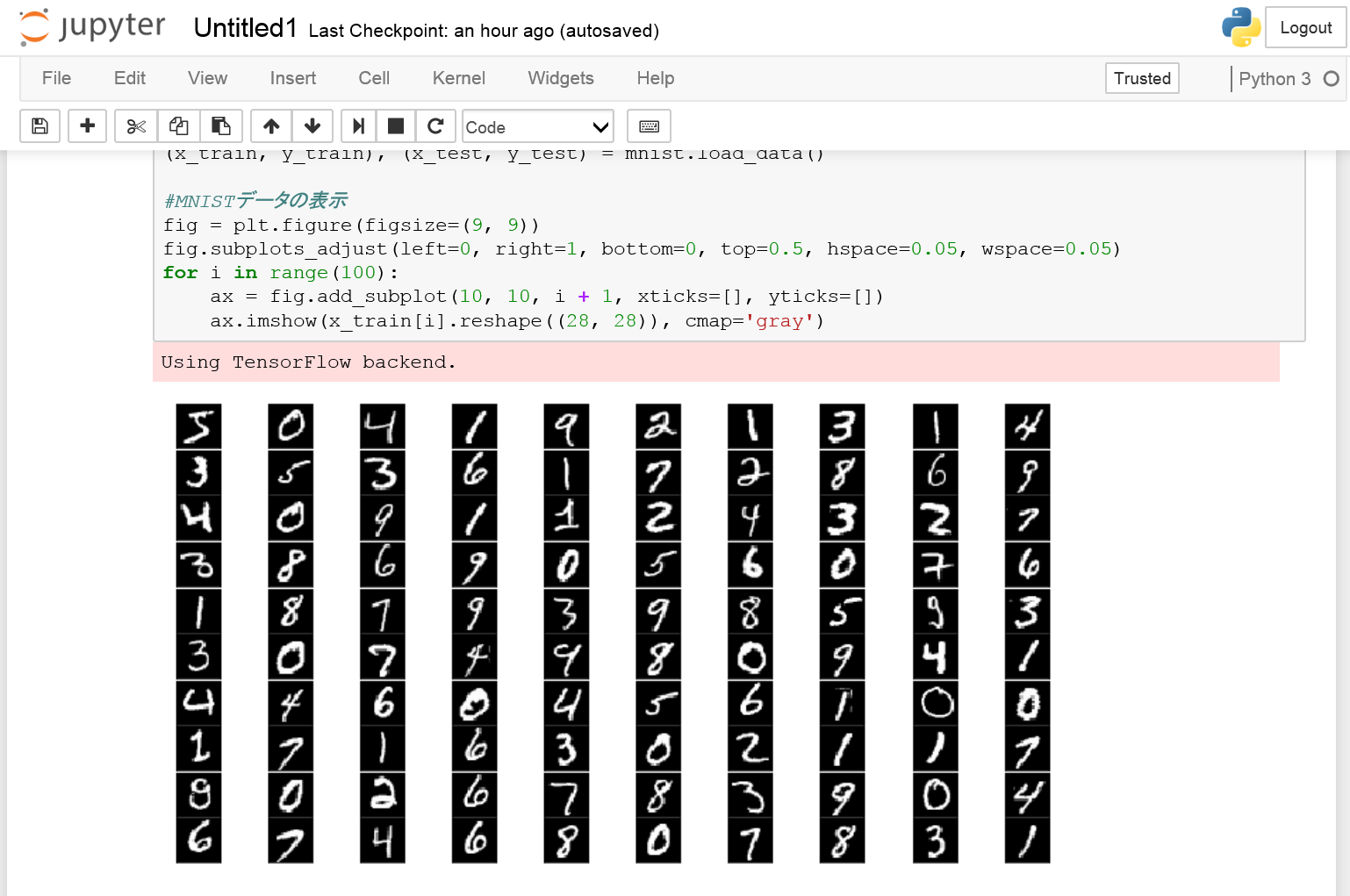
Jupyter Notebookを開いて以下のコードを入力し実行します。mnist.load_data()は初回時にデータをダウンロードしてくる為多少の時間を要します。実行が終わると学習データの先頭100画像が表示されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
%matplotlib inline import keras from keras.datasets import mnist from keras.utils.np_utils import to_categorical import matplotlib.pyplot as plt #Kerasの関数でデータの読み込み。データをシャッフルして学習データと訓練データに分割してくれる (x_train, y_train), (x_test, y_test) = mnist.load_data() #MNISTデータの表示(学習データの最初の100枚を表示) fig = plt.figure(figsize=(9, 9)) fig.subplots_adjust(left=0, right=1, bottom=0, top=0.5, hspace=0.05, wspace=0.05) for i in range(100): ax = fig.add_subplot(10, 10, i + 1, xticks=[], yticks=[]) ax.imshow(x_train[i].reshape((28, 28)), cmap='gray') |
(2)出力結果
以下の通りランダムに振られた手書き文字画像が確認できました。
2.モデル作成とコンパイル
Jupyter Notebookの次セルに以下のコードを入力し実行します。実行は瞬時に終わります。実行後特に画面表示されるものはありません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from keras.models import Sequential from keras.layers import Dense, Activation from keras.utils.np_utils import to_categorical import numpy as np #mnistデータの正規化 num_classes = 10 x_train1 = x_train.reshape(60000, 784) x_test1 = x_test.reshape(10000, 784) x_train1 = x_train1.astype('float32') x_test1 = x_test1.astype('float32') x_train1 /= 255 x_test1 /= 255 y_train = y_train.astype('int32') y_test = y_test.astype('int32') y_train = to_categorical(y_train, num_classes) y_test = to_categorical(y_test, num_classes) #モデル作成 model = Sequential([ Dense(512, input_shape=(784,)), Activation('sigmoid'), Dense(10), Activation('softmax')]) #コンパイル model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy']) |
上記コードではトレーニングデータとテストデータの正規化、モデルの作成とコンパイルをしています。
3.トレーニング
(1)実行コード
Jupyter Notebookの次セルに以下のコードを入力し実行します。
|
1 2 3 4 5 |
batch_size = 128 epochs = 20 history = model.fit(x_train1, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test1, y_test)) |
上記コードでは作成したモデルとmnistデータを使用して機械学習を実行し結果をhistoryに代入しています。
(2)実行結果
以下のlossとaccがセットになった実行状況がepochs で指定された回数分出力されてます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
Train on 60000 samples, validate on 10000 samples Epoch 1/20 60000/60000 [==============================] - 7s - loss: 1.9578 - acc: 0.5408 - val_loss: 1.6228 - val_acc: 0.7072 Epoch 2/20 60000/60000 [==============================] - 7s - loss: 1.3877 - acc: 0.7527 - val_loss: 1.1602 - val_acc: 0.8030 Epoch 3/20 60000/60000 [==============================] - 7s - loss: 1.0370 - acc: 0.8040 - val_loss: 0.8972 - val_acc: 0.8281 Epoch 4/20 60000/60000 [==============================] - 7s - loss: 0.8369 - acc: 0.8286 - val_loss: 0.7459 - val_acc: 0.8465 Epoch 5/20 60000/60000 [==============================] - 7s - loss: 0.7170 - acc: 0.8439 - val_loss: 0.6508 - val_acc: 0.8568 Epoch 6/20 60000/60000 [==============================] - 7s - loss: 0.6387 - acc: 0.8537 - val_loss: 0.5868 - val_acc: 0.8665 Epoch 7/20 60000/60000 [==============================] - 7s - loss: 0.5839 - acc: 0.8616 - val_loss: 0.5404 - val_acc: 0.8706 Epoch 8/20 60000/60000 [==============================] - 7s - loss: 0.5436 - acc: 0.8672 - val_loss: 0.5058 - val_acc: 0.8759 Epoch 9/20 60000/60000 [==============================] - 7s - loss: 0.5126 - acc: 0.8717 - val_loss: 0.4789 - val_acc: 0.8809 Epoch 10/20 60000/60000 [==============================] - 7s - loss: 0.4879 - acc: 0.8762 - val_loss: 0.4571 - val_acc: 0.8851 Epoch 11/20 60000/60000 [==============================] - 7s - loss: 0.4681 - acc: 0.8794 - val_loss: 0.4395 - val_acc: 0.8876 Epoch 12/20 60000/60000 [==============================] - 7s - loss: 0.4517 - acc: 0.8822 - val_loss: 0.4244 - val_acc: 0.8905 Epoch 13/20 60000/60000 [==============================] - 7s - loss: 0.4378 - acc: 0.8840 - val_loss: 0.4122 - val_acc: 0.8917 Epoch 14/20 60000/60000 [==============================] - 7s - loss: 0.4260 - acc: 0.8859 - val_loss: 0.4025 - val_acc: 0.8934 Epoch 15/20 60000/60000 [==============================] - 7s - loss: 0.4158 - acc: 0.8879 - val_loss: 0.3937 - val_acc: 0.8936 Epoch 16/20 60000/60000 [==============================] - 7s - loss: 0.4068 - acc: 0.8892 - val_loss: 0.3844 - val_acc: 0.8952 Epoch 17/20 60000/60000 [==============================] - 7s - loss: 0.3989 - acc: 0.8909 - val_loss: 0.3773 - val_acc: 0.8969 Epoch 18/20 60000/60000 [==============================] - 7s - loss: 0.3920 - acc: 0.8923 - val_loss: 0.3710 - val_acc: 0.8982 Epoch 19/20 60000/60000 [==============================] - 7s - loss: 0.3857 - acc: 0.8929 - val_loss: 0.3652 - val_acc: 0.8978 Epoch 20/20 60000/60000 [==============================] - 7s - loss: 0.3801 - acc: 0.8941 - val_loss: 0.3602 - val_acc: 0.8993 |
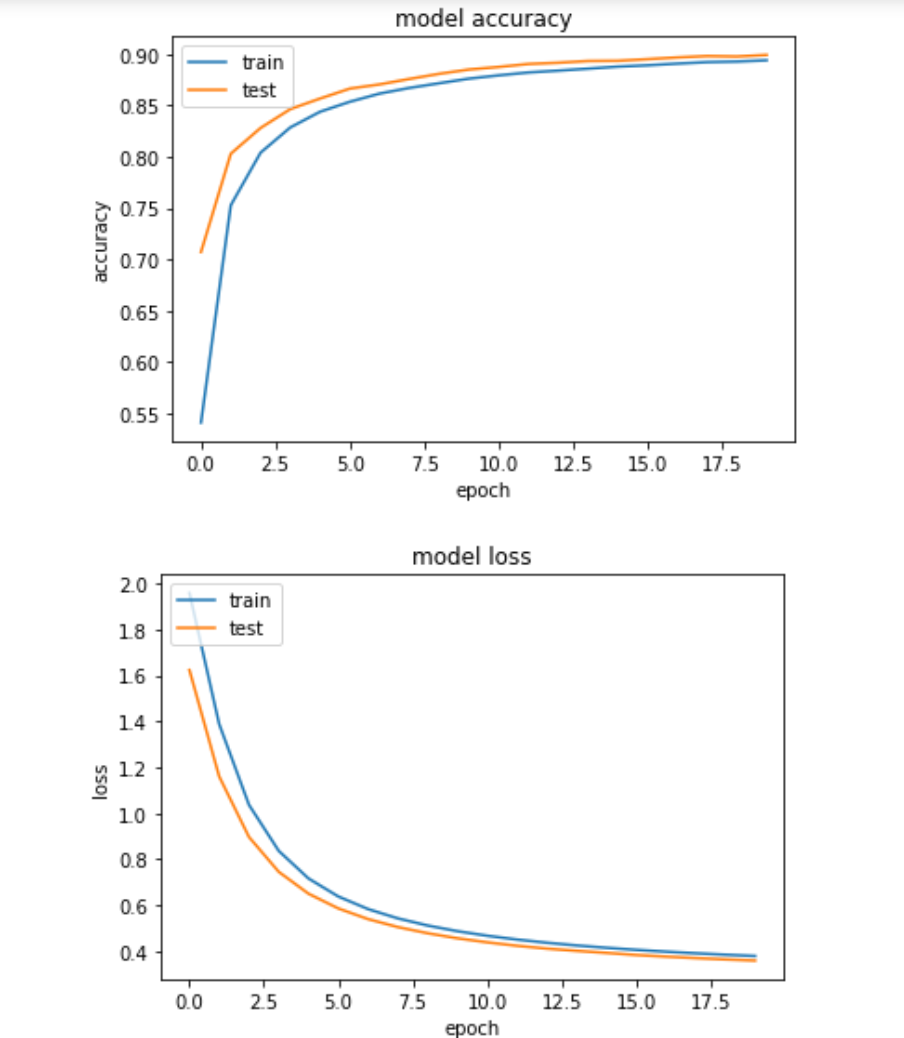
20回のトレーニングの結果、loss(損失率):0.3602、Acc(正解率):0.8993になりました。
4.機械学習結果のグラフ化
(1)実行コード
Jupyter Notebookの次セルに以下のコードを入力し実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#ACC plt.plot(history.history['acc']) plt.plot(history.history['val_acc']) plt.title('model accuracy') plt.ylabel('accuracy') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='upper left') plt.show() #loss plt.plot(history.history['loss']) plt.plot(history.history['val_loss']) plt.title('model loss') plt.ylabel('loss') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='upper left') plt.show() |
(2)実行結果
繰り返し学習によるAcc(正解率)とloss(損失率)の収束状況がグラフで確認できます。
5.機械学習判定結果の評価
テストデータ10000枚の中からランダムに10枚を抽出し、作成したモデルで機械学習の判定結果を評価してみます。
(1)評価データ抽出と表示
Jupyter Notebookの次セルに以下のコードを入力し実行します。
|
1 2 3 4 5 6 7 8 9 10 11 |
import random #新しいウィンドウを描画 fig = plt.figure(figsize=(9,9)) fig.subplots_adjust(left=0, right=1, bottom=0, top=0.5, hspace=0.05, wspace=0.4) #テストデータをランダムに選択する準備 tstlist = list(range(10000)) random.shuffle(tstlist) #ランダムに選択した10件を検証データとして表示 for i in range(10): ax = fig.add_subplot(1, 10, i + 1, xticks=[], yticks=[]) ax.imshow(x_test[tstlist[i]].reshape((28, 28)), cmap='gray') |
(2)抽出画像出力
以下の10枚の画像がランダムに抽出されました。
![]()
(3)作成したモデルによる判定
Jupyter Notebookの次セルに以下のコードを入力し実行します。
|
1 2 3 4 5 6 |
for i in range(10): data = np.asarray(x_test1[tstlist[i]]).reshape((-1, 784)) res = model.predict([data])[0] y = res.argmax() per = round(float(res[y] * 100),3) # --- 正解率を小数3桁精度(四捨五入)で求める print("{0} ({1} %)".format(y, per)) |
(1)で抽出した10枚の画像データを対象にpredictで判定を行い結果をprint文で出力しています。
(4)実行結果
以下の結果が出力されました。左から数えた画像データに対し上から数えた出力結果が対応しています。機械学習モデルが出力した結果の右側コメントは、私が画像データから判断した回答との正誤です。○が正解,×が不正解です。
|
1 2 3 4 5 6 7 8 9 10 |
8 (70.627 %) #×(人の判定結果と不一致) 5 (86.986 %) #○(人の判定結果と一致) 3 (97.57 %) #○ 0 (99.805 %) #○ 5 (95.225 %) #○ 6 (98.589 %) #○ 6 (89.061 %) #○ 7 (41.658 %) #× 1 (76.066 %) #○ 8 (91.906 %) #○ |
(5)評価
今回の抽出データでは10枚中8枚が正解で正解率は80%になりました。作成したモデルの正解率:0.8993に近い値です。間違えたデータは下記2枚です。
1番目のデータ:70%の確率で8と判定されました。わかりにくいですが3のようです。
8番目のデータ:41%の確率で7と判定されましたが2のようです。
今回は10枚のデータによる判定ですのでACCとの誤差が10%程度ありますが評価する枚数を増やせば結果はACCの値に近づきます。上記画像の形状と判定結果を対比してみると今回の機械学習モデルはまずまずの判定結果と評価できます。
6.参考にさせて頂いたサイト
ディープラーニング実践入門 〜 Kerasライブラリで画像認識をはじめよう!
ありがとうございます。